FPGA-功耗设计
FPGA-功耗设计
在 FPGA 的选型与设计中,功耗是一个极为关键但又经常被忽略的指标。
与 MCU 或 ASIC 不同,FPGA 的功耗并不是固定的,而是由器件工艺、设计利用率、工作频率、GT(高速串行收发器)使用数量等多方面共同决定。
本篇文章将系统讲解 FPGA 功耗的构成、影响因素、估算与实测方法,以及在工程中如何科学比较不同 FPGA 的功耗表现。
一、FPGA 功耗的两大组成部分
FPGA 的功耗通常可以分为 静态功耗(Static Power) 和 动态功耗(Dynamic Power) 两部分:
| 项目 | 含义 | 影响因素 | 典型大小 |
|---|---|---|---|
| 静态功耗 | 上电、配置完成后即使逻辑不运行也存在的功耗 | 工艺节点、芯片规模、电压、温度 | mW ~ 几百 mW |
| 动态功耗 | 运行时因逻辑翻转、时钟切换、GT口工作而产生 | 逻辑利用率、时钟频率、GT 通道数量、I/O 速率 | 几百 mW ~ 数 W,甚至十几 W |
🤞总功耗 = 静态功耗 + 动态功耗
静态功耗主要取决于工艺与芯片体积;动态功耗则取决于设计实现情况,是后期优化的重点。
二、静态功耗的比较方法
静态功耗的比较非常适合在早期选型阶段使用,可以帮助你快速锁定更节能的架构。
2.1 使用 Xilinx Power Estimator(XPE) 工具
步骤:
- 打开 XPE,选择器件型号;
- 不输入任何逻辑(利用率 0%),设置电压与温度;
- 查看工具计算出的 Static Power,即可得到纯静态功耗的对比值。
2.2 工艺节点对静态功耗的影响
举例对比不同工艺节点下的静态功耗(典型值):
| 器件型号 | 工艺 | 静态功耗(典型) |
|---|---|---|
| XC7K325T(Kintex-7) | 28nm | 0.5–0.8 W |
| XCKU5P(UltraScale+) | 16nm FinFET | 0.15–0.25 W |
| VCK190(Versal) | 7nm FinFET | 0.1–0.3 W |
可以看到,随着工艺的演进(28nm → 16nm → 7nm),静态功耗显著下降。
所以,在功耗敏感场合,优先选择新工艺架构(如 UltraScale+) 是非常有效的手段。
三、动态功耗的估算方法
动态功耗决定了设计的实际能耗,估算方法可以分为三个阶段:
3.1 前期粗估(架构评估阶段)
使用 XPE 工具,填写以下信息:
- LUT / FF 利用率
- DSP 使用数量
- BRAM 数量
- 时钟频率
- GT 通道数量和速率
- IO 速率
XPE 会输出逻辑、时钟、存储器、GT 等模块的动态功耗粗估值,帮助你初步比较不同型号的功耗水平。
3.2 综合布线后的精估(实现后阶段)
使用 Vivado Power Analyzer:
- 打开综合布线完成的
.dcp文件; - 导入仿真或实测得到的 VCD/SAIF 切换活动文件;
- 工具会根据实际切换率、时钟树、GT 工作状态精确计算动态功耗。
这种方式的误差通常在 10–20% 以内,是工程中最常用的功耗评估方法。
3.3 板级实测(最终验证)
最终功耗以实际测量为准:
- 使用板上 PMBus 电源监控芯片(如 TI INA226)读取各个电源 Rail 的电流;
- 或用示波器、电源分析仪监控上电与运行时的功耗曲线;
- 特别要监控 GT 电源域(MGTAVCC / MGTAVTT)功耗变化,GT 启动会明显拉高功率。
四、GT(高速收发器)功耗的特殊性
GT 是 FPGA 功耗中非常重要的一块,尤其是在 JESD204B、PCIe、10G/25G 以太网等应用中。
| 通道类型 | 速率 | 单通道功耗(近似) |
|---|---|---|
| GTP(Artix-7) | 6.6 Gbps | |
| GTX(Kintex-7) | 0–12 Gbps 可调 | 250 mW |
| GTH(UltraScale、UltraScale+) | 0~16 Gbps 可调 | 160 mW |
| GTY(UltraScale+) | 32 Gbps | |
| GTM(Versal) | 58 Gbps |
例如,4 条 10G GTX 的功耗大约在 0.4~0.6 W,如果开满几十条 GT,功耗可以直接上升到数瓦甚至十几瓦。因此,GT 通道数量与速率,是功耗评估中最关键的变量之一。
- 不同的设置会改变其功耗特性
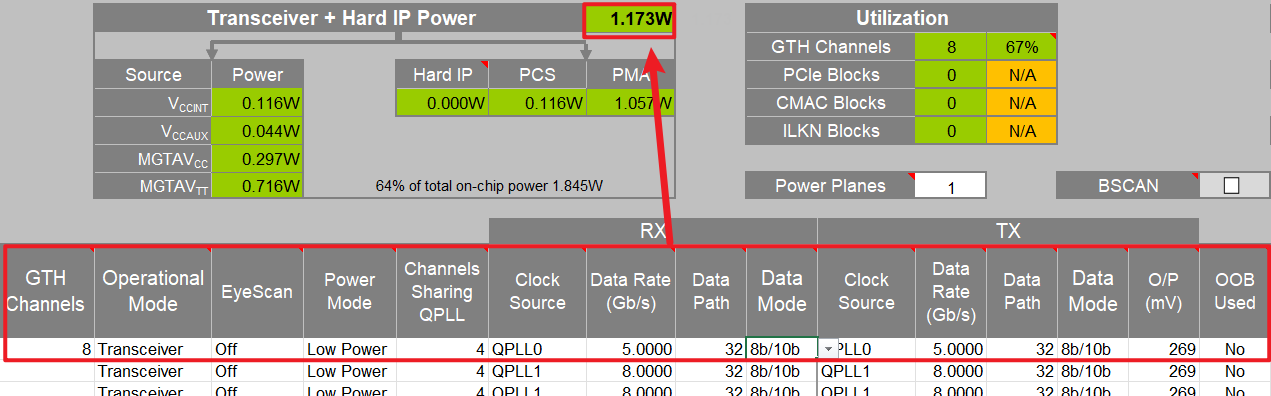
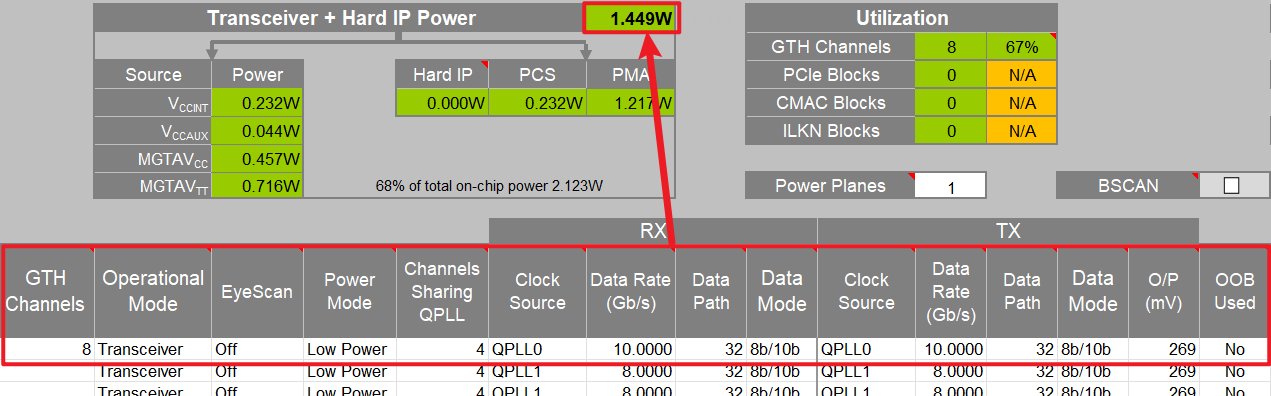
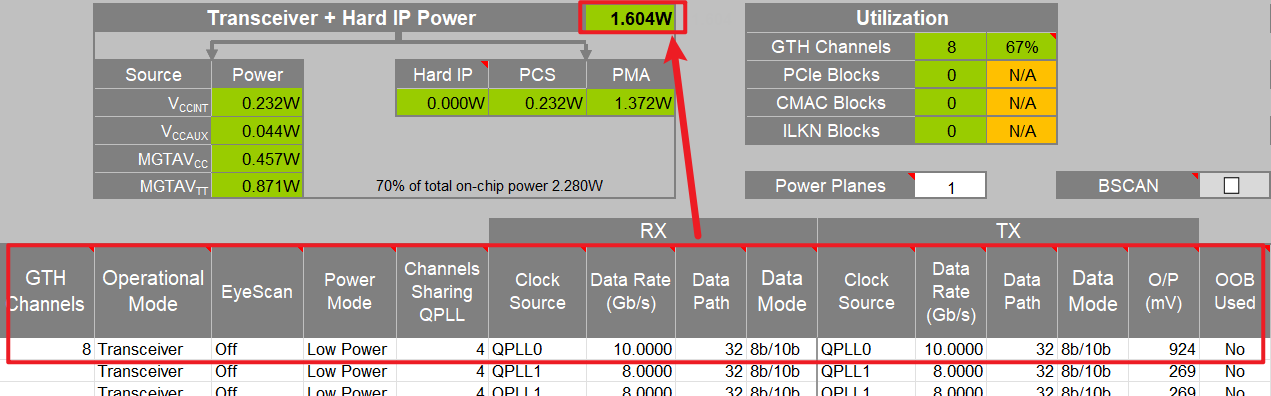
Clock Source有几个选项:
CPLL
每个通道自带的 Channel PLL,粒度最细,通道之间互不共享。适合中低速、各通道速率/参考时钟不一致的场景。优点是独立灵活;缺点是功耗较高(每通道都要开一颗 PLL)、可达速率上限较低。QPLL0 / QPLL1(UltraScale/UltraScale+ 才有两个 QPLL)
每个 Quad(4 通道)共享的 Quad PLL。一个 Quad 内的多个通道可共用同一 QPLL,功耗能摊薄,抖动性能也更好。
QPLL0 与 QPLL1 是两套可并行存在的 QPLL,VCO/分频覆盖范围不同,用于适配不同的参考时钟与线速组合,gpt回答的是QPLL1更适应于更高传输速度的情况,但是实际仿真中会发现,在Data Rate选择很高的时候,反而QPLL1会标黄弹出警告,目前不清楚为啥。
其次是Data Rate的速度和芯片选型也有关系,如下所示,最快的是-2或-3.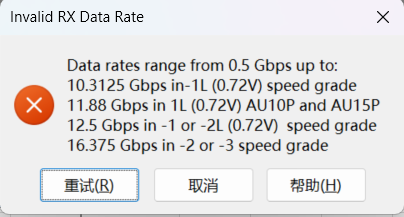
Power Down
该通道的收发器时钟源关闭,用于建模通道关闭时的功耗。
五、功耗比较的推荐工程流程
在实际选型和设计中,可以采用以下分阶段流程来比较功耗:
- 确定系统架构与 GT 需求
例如:4 路 10G、8 路 JESD204B、PCIe x8 等 - 初步筛选系列
选取 2~3 个架构(如 Kintex-7、UltraScale+、Versal)作为候选。 - 使用 XPE 估算静态功耗
快速对比工艺与封装差异带来的基础功耗。 - 设定典型设计参数,估算动态功耗
假设逻辑利用率、时钟频率、GT 通道数等,使用 XPE 进行初步比较。 - Vivado Power Analyzer 精估
使用实际设计的.dcp+ VCD 做精确的功耗计算。 - 板级实测确认
使用 PMBus/示波器实测,验证与工具估算的差异。
六、封装与功耗的关系
封装大小也会间接影响功耗:
- 封装越大 → 电源 Rail 越多,静态功耗略升;
- 大封装通常暴露更多 GT 通道 → 动态功耗也可能显著增加;
- 在 Xilinx 的器件里,同一个 Die 不同封装的静态功耗差距不大,但 实际能用的 GT 数量不同,导致动态功耗差异巨大。
所以要选封装小的。
七、功耗优化与选型建议
- 优先使用先进工艺
例如 UltraScale+(16nm FinFET)相比 7 系列(28nm),静态功耗大幅下降。 - 控制 GT 通道数量
少量高性能 GT 比大量低速 GT 更省功耗。 - 使用 Vivado Power Analyzer + VCD
这是评估实际设计功耗的最可靠方式。 - 尽早进行功耗评估
设计后期才考虑功耗,往往代价巨大。早期就要把功耗估算放进选型环节。
参考资料
- Xilinx Power Estimator (XPE)
- Vivado Power Analyzer User Guide
- UG578 - UltraScale Architecture GTY Transceivers
- UG476 - 7 Series GTX/GTP Transceivers
「比较 FPGA 功耗,不是看一眼 datasheet 就行,而是一个从静态→动态→实测的完整工程过程。」