FPGA中的IP核
FPGA中的IP核
一、IP核
1.1 IP核是什么
1.2 为什么要用IP核
1.3 IP核和原语的实质性区别是什么
一句话区别:原语是硬件底层资源的最小封装;IP 核是基于原语或行为描述封装的高层可配置逻辑模块。
原语(Primitive)的特点:小 & 底层 & 用户不可配置
- 底层、固定、不可配置:通常由 FPGA 厂商提供,和芯片架构直接对应。
- 编译器内置支持,如 Xilinx 的
IBUFDS、BUFG,RAM32X1D,FDRE等。 - 不需要生成或综合,直接通过综合器(如 Vivado Synthesis)映射到物理资源。
- 作用相当于“门级模块”或“标准单元”,如 LUT、寄存器、IO buffer、时钟 buffer。
IP核(IP Core)的特点:大 & 高层 & 用户可配置
- 高层封装模块:可以由多个原语、HDL模块、状态机等组合而成。
- 用户可配置:通过 Vivado IP Catalog 的 GUI 设定端口数量、参数宽度、行为选项等。
- 需要先在 Vivado 中 “Generate Output Products” 才能综合、实现。
- 通常带有
.xci(Vivado IP 描述文件)、.v(包装模块)、.dcp(综合后网表)等文件。
二、IP核两种使用方式
在verilog代码中直接写IP核语句:
例如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17module Clk_Divider#
(
parameter DEBUG_ENABLE = 1'b1
)
(...
);
...
generate
if (DEBUG_ENABLE == 1'b1) begin : debugcore
// 添加 ILA IP,ChipScope 观察信号
ila_0 ila_0_0 (
.clk(clk_i), // ILA 时钟
.probe0(div2hz_o), // 输入探针 0
.probe1({div2_o, div3_o, div4_o, div8_o}) // 输入探针 1,宽度为4
);
end
endgenerate在这里使用了一个generate if语句来实现测试的时候,我加上ILA这个IP,来进行对信号的实时监测,而工程落地后,我可以选择将DEBUG_ENABLE置0来实现让ILA这个IP核不工作。
那么如何去查一个没用过的IP核呢(怎么用,代码怎么写都不知道)。

先点击IP Catalog打开IP核库,然后搜索需要的IP,双击编辑IP核

然后点击OK,并generate,这个IP核就添加到工程中了。但此时还是游离在外的状态,下面还需要将其添加到工程中接线:

点击箭头,Show IP Hierarchy,查看这个ip的.v头文件。

此时就可以直接用其头文件,在自己的文件中例化这个IP核,然后正常使用了,添加成功后,ip将不再游离在外,会被添加到工程之中。
在Block Design中,使用 Vivado 的 IP Integrator图形化添加IP核:
- 打开 Block Design,点击 “Add IP”,搜索并添加
ILA。 - 自动配置探针宽度、数量,并连接到需要监控的信号。
- 启用 Debug Bridge(如有 JTAG 接入需求)。
- 打开 Block Design,点击 “Add IP”,搜索并添加
三、常见的IP公版IP核
3.1 ila_0
功能:ILA(Integrated Logic Analyzer)是 Vivado 提供的一个调试 IP 核,能够:
- 实时采集并缓存 FPGA 内部信号
- 通过 JTAG 与 Vivado Hardware Manager 建立通信
- 显示波形、设置触发条件,进行逻辑行为分析
它相当于FPGA 内嵌的逻辑分析仪。
例化示例:
1 | ila_0 ila_0_0 ( |
| 端口名称 | 类型 | 说明 |
|---|---|---|
.clk |
input |
采样时钟,所有探针数据在此时钟下同步采样 |
.probe0 |
input [0:0] |
单位宽信号,可用于控制信号、标志位 |
.probe1 |
input [3:0] |
4位并行信号,典型用法是多个分频信号或控制信号组合 |
.trigger |
input(可选) |
外部触发条件,通常配合 Hardware Manager 设置 |
.capture |
input(可选) |
控制是否采样数据 |
.resetn |
input(可选) |
对 ILA 内部状态机进行复位 |
.qual |
input(可选) |
数据限定条件控制,只在 qual 有效时采样 |
最方便的方式还是直接在block design里面添加ila的ip核,要注意,不管怎么添加,有一点非常重要:
那就是ILA的时钟一定要往高了给,并且尽量要给所测信号最高速度的整数倍,并且3倍以上,比如测的是60MHz的信号,那ila的时钟就尽量给300MHz,否则很有可能这个ila因为某些原因都不工作,或者工作的是乱的。这点很重要
3.2 clk_wiz

功能:clk_wiz(Clocking Wizard)是 Vivado 提供的时钟管理 IP 核,能够:
- 对输入时钟进行频率综合,生成多路不同频率的输出时钟
- 支持相位偏移、占空比调整
- 基于 MMCM 或 PLL 原语实现,提供 locked 信号指示时钟锁定状态
它相当于 FPGA 内部的时钟管理单元(CMT)的封装。
1 | clk_wiz_0 clk_wiz_0_inst ( |
| 端口名称 | 类型 | 说明 |
|---|---|---|
| .clk_in1 | input | 主输入时钟,本例为 480MHz,来自单端时钟引脚 |
| .reset | input | 复位信号,高电平有效,复位内部 MMCM |
| .clk_out1 | output | 输出时钟1,480MHz,相位偏移 90 度 |
| .clk_out2 | output | 输出时钟2,120MHz,无相移 |
| .clk_out3 | output | 输出时钟3,40MHz,无相移 |
| .clk_out4 | output | 输出时钟4,80MHz,无相移 |
| .clk_out5 | output | 输出时钟5,480MHz,无相移 |
| .locked | output | 锁定指示信号,高电平表示所有输出时钟已稳定 |
使用注意事项:
- 在使用输出时钟之前,必须等待 locked 信号拉高,表示 MMCM 已完成锁定,输出时钟频率和相位稳定可用。
- reset 为高有效(默认,但是可配置),复位期间 locked 会拉低,所有输出时钟不可用。
- clk_out1 配置了 90 度相位偏移,常用于 DDR 接口等需要相位对齐的场景。
3.3 Block Memory Generator
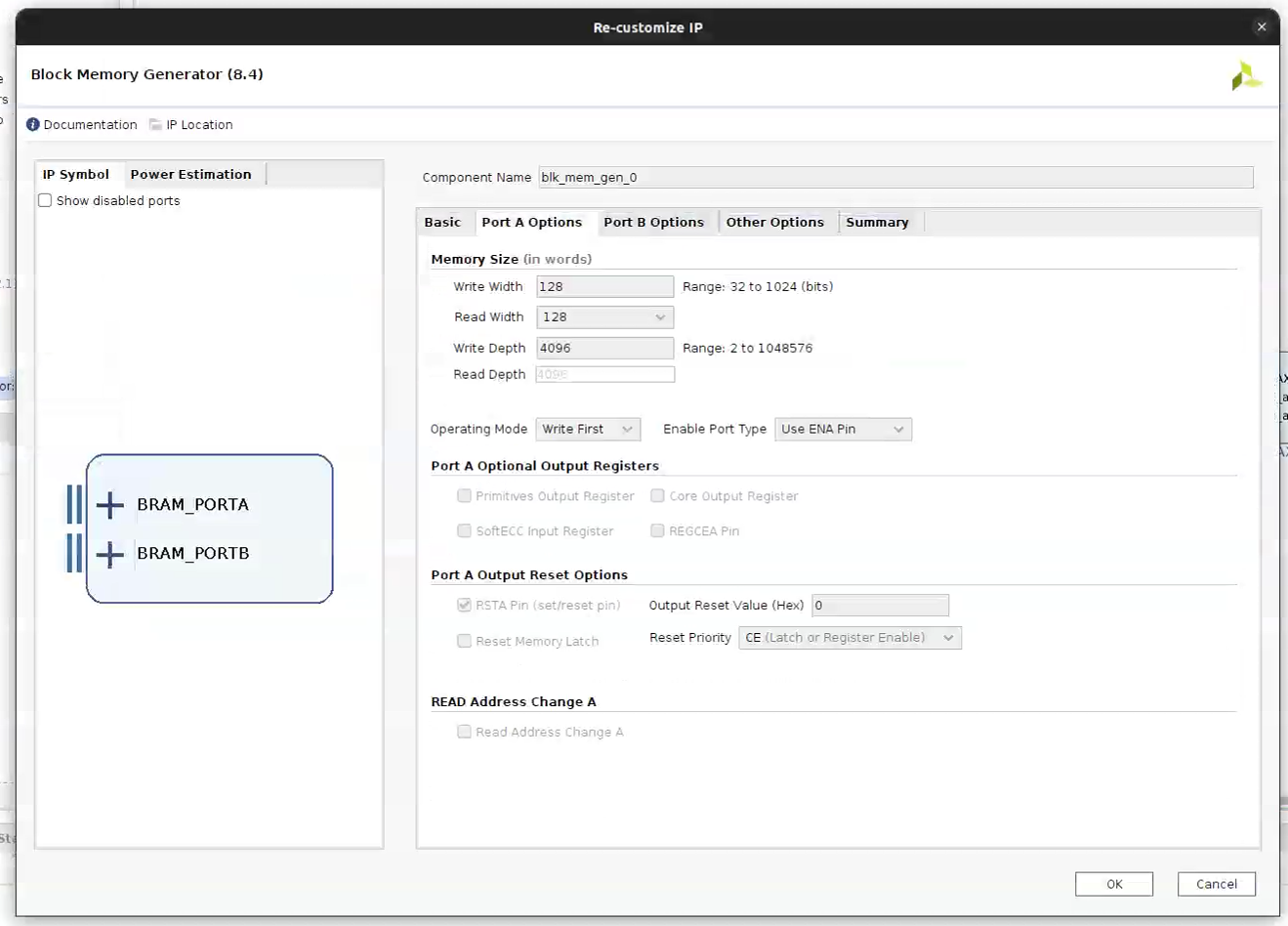
这里write width 和 write depth在ip刚添加进去的时候都是灰色不能改变的,这是因为Block Memory Generator这个ip是跟着AXI BRAM controller的输出来变的,vivado添加这些ip之后没有进行Validate design(F6),因此软件并不知道前后的逻辑关系,只需要进行Validate design操作,即可将里面的参数自动改变。
其次Write Depth和Read Depth深度大小是和Address Editor中分配的大小相关,比如这里设置64K,也能看到:
Master Base Address (0xC000_0000): 主设备访问这个BRAM时的起始地址。
Master High Address (0xC000_FFFF): 访问范围的结束地址。
也就是65536个Byte字节,65536/1024=64,正好对应64K个字节。
注意 !:AXI总线采用字节寻址,一个地址对应1字节(8位)。

那Block Memory Generator是怎么算的呢128*4096/8=65536,这确实对应了64K的地址大小,但是这不是有两个port吗,不应该需要128K的地址大小?
其实不是,两个Port访问的是同一块物理存储,不是各自独立的两块内存。
可以理解成一个房间有两扇门,房间还是那一个,大小不变。Port A和Port B只是提供了两个同时访问的通道,数据存在同一片BRAM里。所以总容量还是 128 x 4096 / 8 = 64KB,地址空间分配64K就是对的。
双端口的意义在于:Port A和Port B可以同时读写,比如Port A给AXI总线用,Port B自己的逻辑用,两边可以并行访问同一块存储,不需要仲裁。
3.4 AXI BRAM Controller
3.5 AXI Interconnect
四、私有IP
4.1 米联客uiFDMA_v3.1
4.1.1 读写BRAM
uiFDMA一般不单独用,首先需要clk_wiz ip核进行时钟配置,还需要processor system reset进行复位信号设置,然后对于读写BRAM,还需要AXI Interconnect 和 AXI BRAM Controller,这两个是xilinx官方的AXI总线控制器,用于读写bram,使用uiFDMA其实就是简化了对于AXI Interconnect的操作,在最后还需要用Block Memory Generator生成块状BRAM
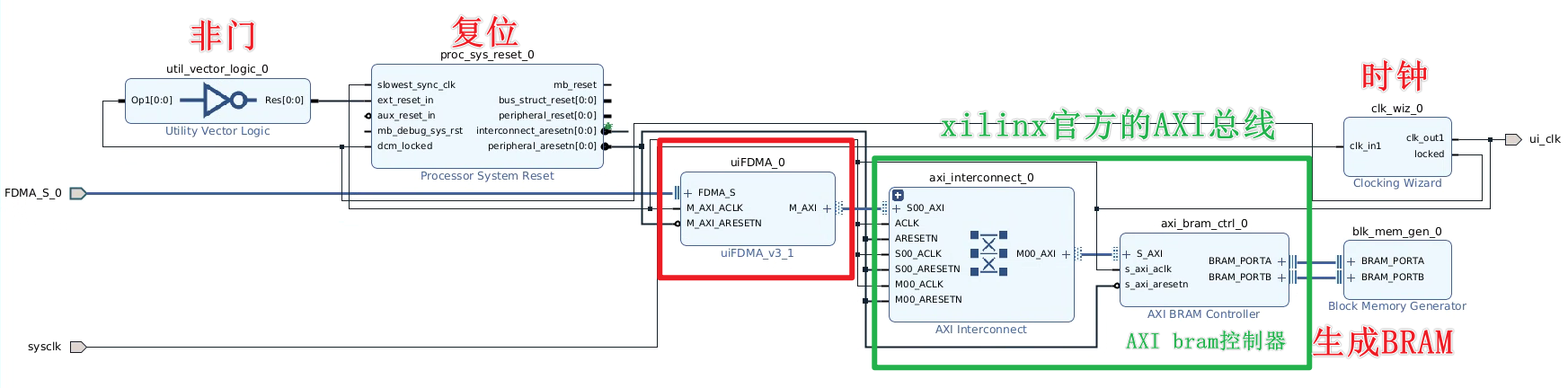
对以上的block design例化:
1 | uiFDMA uiFDMA_u( |
4.1.1.1 完整的调用代码
1 |
|
4.1.1.2 写时序
完整的写时序:
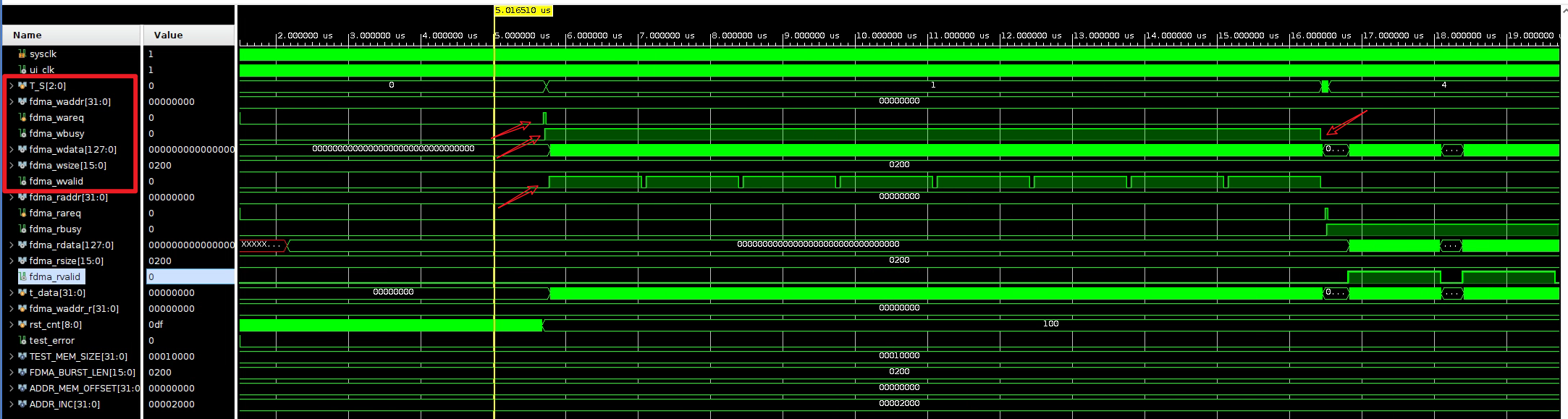
wvalid是写有效标志,为1时并且fdma_wbusy=1才能写进去:
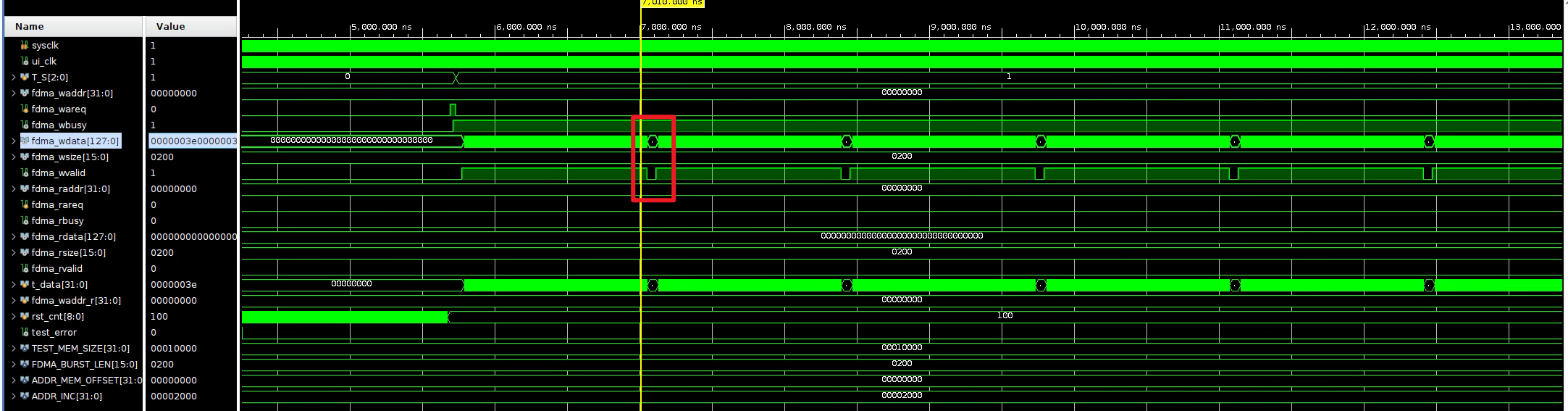
逻辑:fdma_wready 设置为1,当fdma_wbusy=0 的时候代表FDMA 的总线非忙,可以进行一次新的FDMA 传输,这个时候可以设置fdma_wareq=1,同时设置fdma burst 的起始地址和fdma_wsize 本次需要传输的数据大小**(以bytes 为单位)**。当fdma_wvalid=1 的时候需要给出有效的数据,写入AXI 总线。当最后一个数写完后,fdma_wvalid 和fdma_wbusy 变为0。
4.1.1.3 读时序
完整的读时序:

读开始:
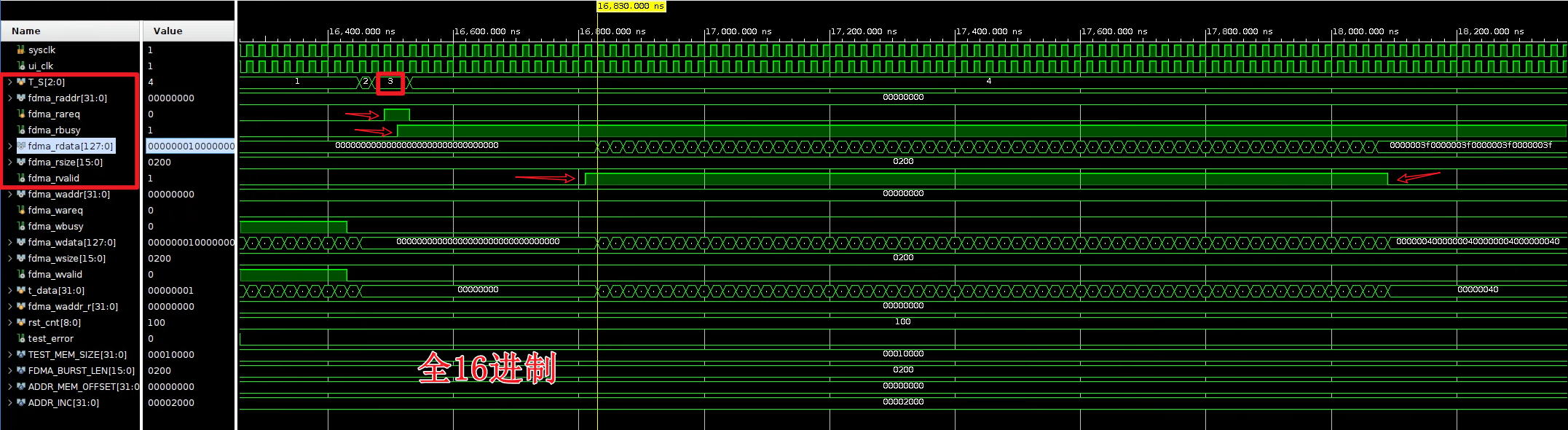
读结束:

fdma_rready 设置为1,T_S状态机为3(read1)、4(read2)时,即为读操作。T_S=read1并且fdma_rbusy=0时,拉高fdma_rareq,此时,设置fdma burst 的起始地址和fdma_rsize 本次需要传输的数据大小(以bytes 为单位)。
这之后IP核立刻输出fdma_rbusy=1,意味着进入地址和长度配置阶段,此时fdma_rvalid=0,意味着还在读配置中,还不能读出数据。直到IP核操作完成,输出fdma_rvalid=1,正式数据读取开始。
数据读取过程中可能会出现fdma_rbusy=1,但是fdma_rvalid=0的情况。这是因为:1. 内存访问延迟 2.AXI互联(Interconnect)的仲裁和路由延迟导致的。只要fdma_rbusy=1就代表读过程没有结束。
当最后一个数写完后,fdma_rvalid 和fdma_rbusy 变为0,读结束。
4.1.1.4 米联客的uiFDMA优势
同样对于AXI4 总线的读操作,AXI4 总线最大的burst lenth 是256,而经过封装后,用户接口的fdma_size 可以任意大小的,fdma ip 内部代码控制每次AXI4 总线的Burst 长度,这样极大简化了AXI4 总线协议的使用。
4.1.2 读写DDR4
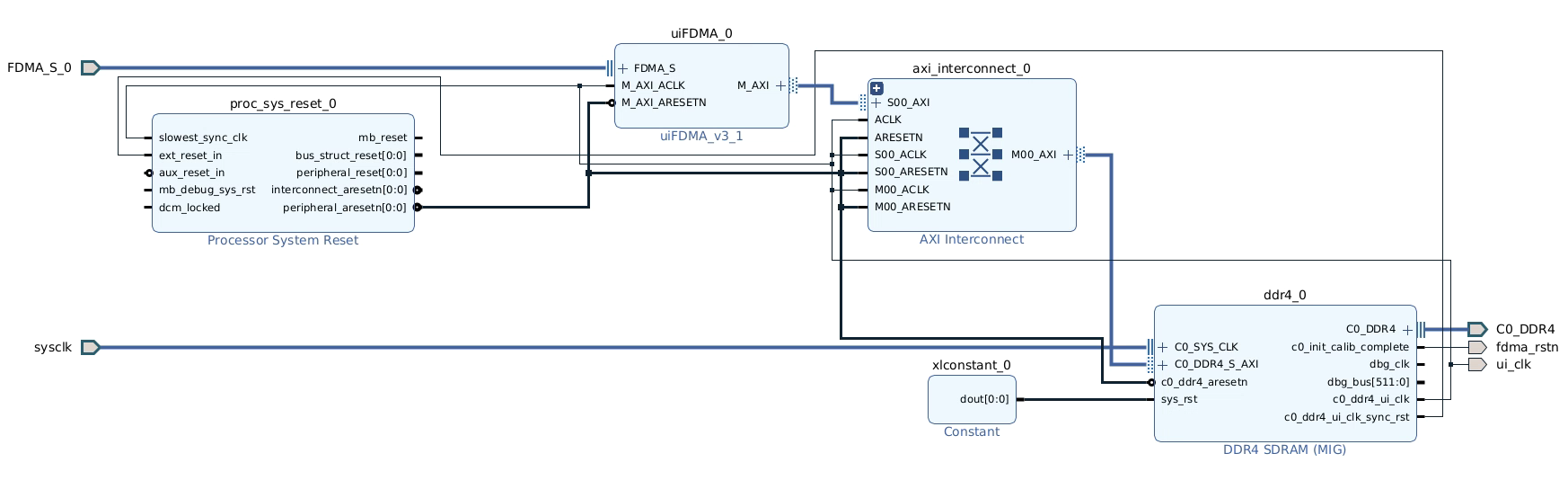
4.1.2.1 完整的调用代码
1 |
|
代码总体和uiFDMA写BRAM没啥区别,都是操作AXI总线。读时序和写时序也是没有变化,只是DDR4接口配置仿真的时候,很麻烦,又有SV文件,还有verilog header文件,并且仿真文件也是从DDR4 SDRAM(MIG) IP核的 open ip example design 中抄过来的
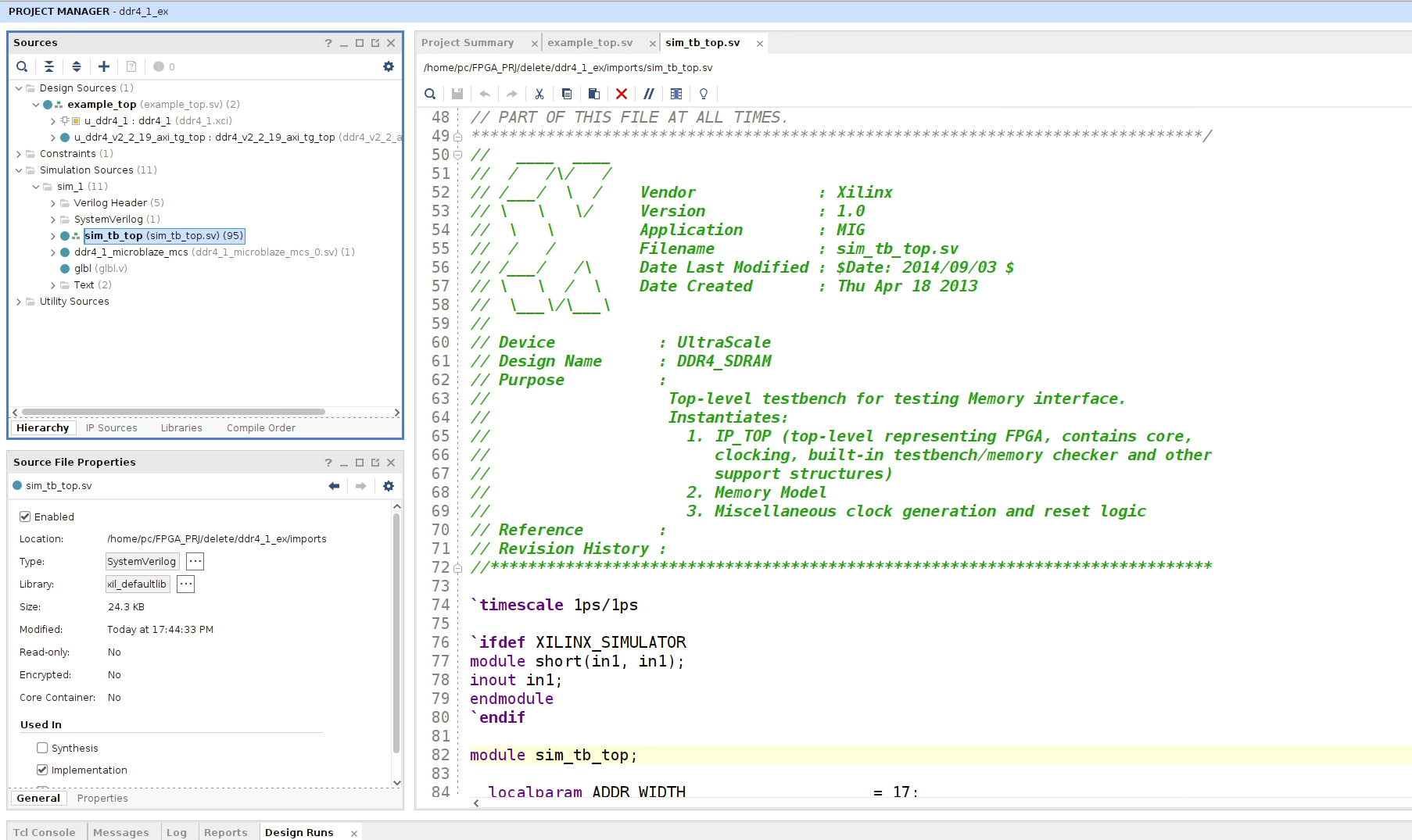
上面是官方IP核例程里面就有关于DDR4 MIG核的仿真操作,和米联客给的基本一样。
4.1.2.2 仿真比较
进行了米联客BD的仿真和XILINX的DDR4 MIG仿真的比较,米联客的仿真如下:
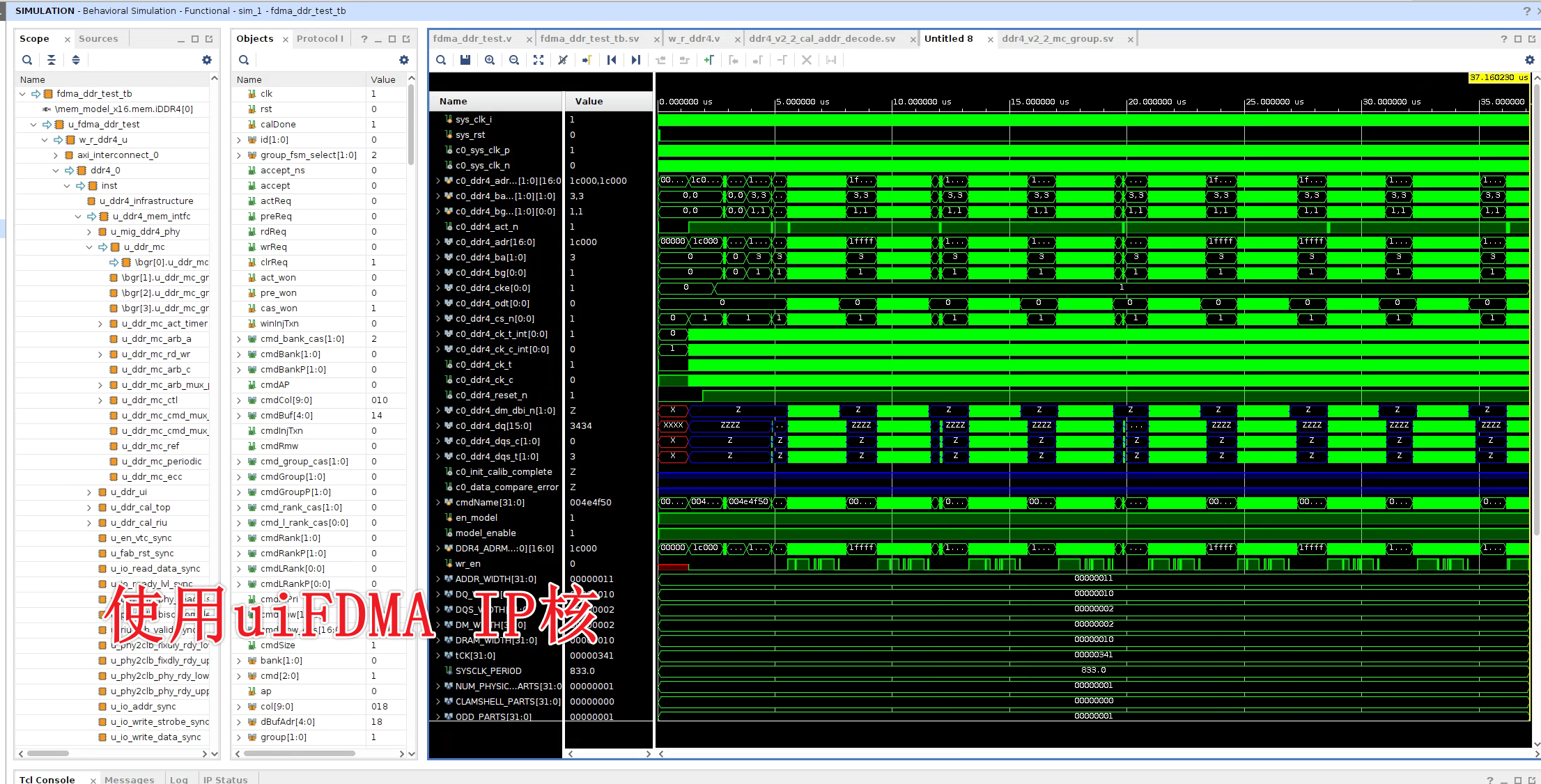
未使用米联客uiFDMA的仿真如下:
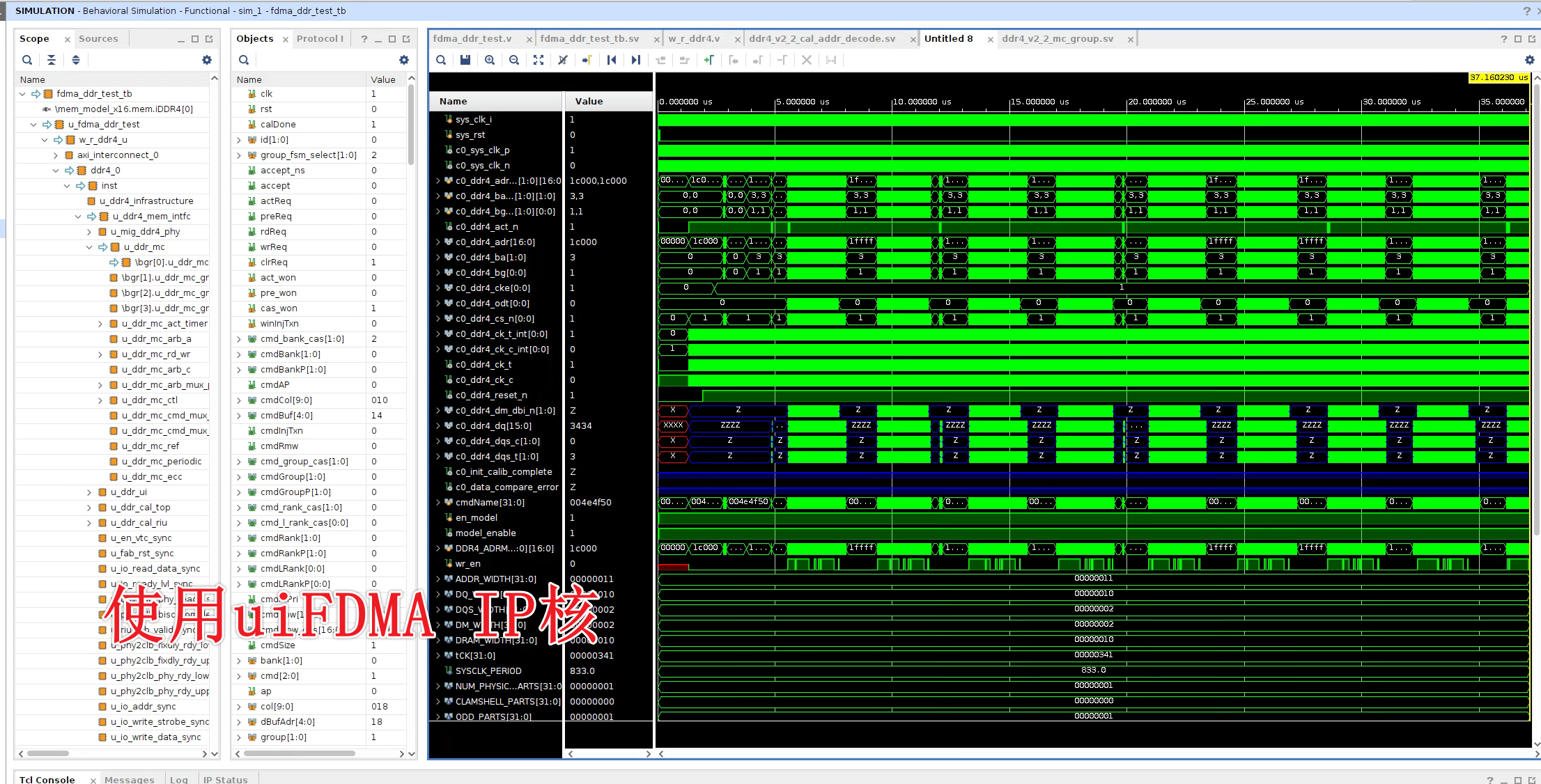
可以看到这两个方法对于DDR4 MIG核操作基本一致,也就是说uiFDMA在保证操作一致的前提下,优化了使用体验。
4.2 米联客uifdma_dbuf
4.2.1 为什么有了uiFDMA还需要uifdma_dbuf:
FDMA 是 AXI4 总线控制器。 它的职责是把用户简单的读写请求(给个地址、给个长度、给个数据)翻译成 AXI4-Full 协议的复杂时序(AR/AW/R/W/B 五通道握手、burst 切分、outstanding 管理等)。它把 AXI4 的复杂性藏起来,让用户看到一个类似 SRAM 的简单接口。
uifdma_dbuf 是数据流适配器 + 多帧缓存管理器。 它的职责是把用户真实的数据流(比如摄像头按像素连续吐出来的视频流)转换成 FDMA 能接受的”块传输”形态,同时管理多帧循环缓存、帧同步、中断通知等业务逻辑。
打个比方:FDMA 是”快递公司的运输系统”,你告诉它”把这个包裹从 A 送到 B”它就能搞定。但如果你有一条流水线每秒生产 100 个零件,你不能对快递公司说”每个零件单独送一次”,你需要一个”打包仓库”:先把零件攒起来装满一箱,再给快递公司一个运输请求。uifdma_dbuf 就是这个打包仓库。
每一层都解决一个特定的抽象问题。FDMA 解决”AXI4 协议太复杂”,uifdma_dbuf 解决”数据流到块传输的转换 + 业务级的缓存管理”。
uifdma_dbuf 真正多出来的东西:
如果没有 uifdma_dbuf,直接用 FDMA,就要自己写下面这些逻辑:
1. 连续数据流到块传输的转换
FDMA 的接口是”请求一次 burst 传输”风格:置 fdma_wareq = 1 发起请求,等 fdma_wbusy = 1 表示 FDMA 接受了,然后在 fdma_wvalid = 1 的周期里把数据一个一个推给它,传完后 fdma_wbusy = 0 表示完成。每次 burst 传输都是独立的事件。
但用户的实际数据是连续的流。比如摄像头以固定像素时钟吐出来,永远不停。你不能让摄像头等 FDMA——你必须先缓存数据,攒够一个 burst 再让 FDMA 来取。uifdma_dbuf 内部有一个 xpm_fifo_async(从 uidbuf.v 的代码可以看到),用户数据先进 FIFO,当 FIFO 里的数据量超过阈值(FDMA_WX_BURST - 2)就触发 W_REQ,然后状态机给 FDMA 发请求。这个 FIFO 就是流和块之间的缓冲区。
2. 帧缓存管理和地址自增
视频应用通常需要”三缓存”或”N 缓存”机制:当前帧在写的时候,前一帧还在被 PS 端读取,再前一帧已经显示完可以释放。uifdma_dbuf 用 W_BUFSIZE 参数控制缓存帧数,每写完一帧自动切换到下一个缓存地址(fmda_wbufn 计数器),写满 N 帧后循环回到第 0 帧。
地址计算也封装好了:你给定 X_SIZE(每行像素数)、X_STRIDE(行跨度,支持填充)、Y_SIZE(行数)、BASEADDR(基地址),它自己算出每次 burst 的起始地址。直接用 FDMA 的话你得自己维护这些地址计数器。
3. 帧同步
4. 中断通知 PS
每完成一帧传输,uidbufirq.v 生成一个中断(fdma_wirq)持续 60 个时钟,把当前写完的帧号(fmda_wbuf)通过 AXI-Lite 暴露给 PS 端。PS 收到中断后读这个寄存器就知道”第几帧已经写进 DDR 了,可以去读了”。这是一个完整的生产者-消费者通知机制。直接用 FDMA 也得自己做中断生成和寄存器映射。
5. 读写对称
整个 IP 对称提供读通道和写通道。读通道的逻辑是写通道的镜像:FDMA 从 DDR 读回数据放进读 FIFO,用户通过 ud_rx 接口以自己的时钟消费。读通道也有帧同步、缓存管理、中断。一个 IP 搞定双向。
4.2.2 判断要不要用 uifdma_dbuf
看你的数据源是什么形态:
- 数据是块状的(已经攒好了一批,要存进 DDR 或从 DDR 读一批出来):直接用 FDMA
- 数据是流式的(传感器、ADC、网络包连续不断地来):用 uifdma_dbuf
- 需要多帧循环缓存或帧中断通知:用 uifdma_dbuf
- 一次性传输、不涉及帧概念:直接用 FDMA
左边是新的,右边是师兄用的
4.3 xillybus公司
4.3.1 introduction
xillybus公司是一个专门做xilinx FPGA的IP核的公司,核心产品是xillybus xillyusb xillyp2p

Xillybus 公司的三个核心产品分别面向不同的通信场景:
| 产品 | 通信链路 | 通信对象 | 典型带宽 |
|---|---|---|---|
| Xillybus | PCIe / AXI | FPGA <-> PC 主机 | 200~3200 MB/s(取决于 PCIe 代数和通道数) |
| XillyUSB | USB 3.x | FPGA <-> PC 主机 | 最高约 350 MB/s(USB 3.0) |
| Xillyp2p | MGT / 串行并行 IO | FPGA <-> FPGA | 10 Mbit/s ~ 物理链路极限 |
Xillybus 和 XillyUSB 解决的是同一个问题(FPGA 和 PC 之间传数据),区别只在物理层:Xillybus 走 PCIe 总线(需要主板上有 PCIe 插槽),XillyUSB 走 USB 线缆(更灵活但带宽较低)。Xillyp2p 则是 FPGA 之间的点对点通信,比如同一块板子上的两片 FPGA、或者通过光纤连接的远端 FPGA。
4.3.2 这个公司解决了什么问题
FPGA 和 PC 之间的数据通信是一个看似简单实则复杂的工程问题。以 PCIe 为例,如果从 Xilinx 提供的 PCIe hard block 开始自己写,需要处理的事情包括:
TLP 包的封装和解析(Memory Read / Memory Write / Completion 等多种类型),DMA 引擎的设计(发起读写请求、管理 DMA buffer、处理 completion 重排序),BAR 空间映射(配置空间、内存空间的地址分配),中断管理(MSI / MSI-X 中断的生成和响应),流控机制(credit-based flow control),上位机驱动程序的编写(Linux 内核模块或 Windows WDM/WDF 驱动),用户态应用程序接口的设计。
整个链路从 FPGA 硬件到操作系统驱动到用户程序,涉及三个完全不同的技术栈,自己从头做通常需要几个月甚至更久。
Xillybus 把这些全部封装好了。FPGA 工程师只需要往 FIFO 里写数据或从 FIFO 读数据,上位机程序员只需要对设备文件做 read/write,中间的所有协议细节、DMA 管理、驱动程序都由 Xillybus 处理。从”开始集成”到”数据跑通”通常只需要几个小时。
4.3.3 xillybus ip
Xillybus 是以色列 Xillybus 公司开发的商用 FPGA IP 核,核心功能是在 FPGA 和主机(PC)之间建立高速数据通道。它把 PCIe / AXI / USB 3.0 等底层总线协议完全封装,FPGA 侧只暴露标准 FIFO 接口(wr_en / data / full / rd_en / data / empty),上位机侧只暴露设备文件接口(/dev/xillybus_*),应用程序用标准的 open / read / write 就能和 FPGA 交换数据,就像读写一个普通文件或 TCP 流一样。
4.3.3.1 怎么用
- FPGA 侧接口
Xillybus 在 FPGA 侧通过标准 FIFO 和用户逻辑交互。每个数据通道(stream)对应一对 FIFO 信号:
FPGA -> PC 方向(上行,数据采集):
| 信号 | 方向 | 说明 |
|---|---|---|
| user_w_data | FPGA -> Xillybus | 写入 FIFO 的数据 |
| user_w_wren | FPGA -> Xillybus | 写使能,高电平时写入一个数据 |
| user_w_full | Xillybus -> FPGA | FIFO 满标志,满时必须停止写入 |
| user_w_open | Xillybus -> FPGA | 上位机是否打开了对应的设备文件 |
PC -> FPGA 方向(下行,控制指令):
| 信号 | 方向 | 说明 |
|---|---|---|
| user_r_data | Xillybus -> FPGA | 从 FIFO 读出的数据 |
| user_r_rden | FPGA -> Xillybus | 读使能,高电平时读出一个数据 |
| user_r_empty | Xillybus -> FPGA | FIFO 空标志,空时没有数据可读 |
| user_r_open | Xillybus -> FPGA | 上位机是否打开了对应的设备文件 |
用户逻辑只需要关心 full 和 empty 信号,不需要了解 PCIe 协议的任何细节。写数据时检查 full,不满就写;读数据时检查 empty,非空就读。
- 上位机侧接口
Xillybus 的驱动程序(Linux 内核自带 xillybus 模块,Windows 需要安装官方驱动)会在 /dev/ 下创建设备文件,命名格式为 /dev/xillybus_
上位机应用程序用标准文件操作就能收发数据:
1 | # Python 示例:从 FPGA 读取数据(数据采集) |
1 | # Linux 命令行:把 FPGA 数据采集到文件 |
- 自定义 IP 核生成
Xillybus 不是一个固定的 IP 核,而是根据用户需求在线定制的。通过 IP Core Factory(https://xillybus.com/ipfactory/ )可以配置:
通道数量(可以有多个独立的上行/下行通道),每个通道的数据位宽(8 / 16 / 32 / 64 / 128 / 256 bit),每个通道的传输模式(同步/异步),期望带宽(影响 DMA buffer 的分配),目标 FPGA 型号和 PCIe 代数。
配置完成后 IP Core Factory 会即时生成一个定制的 IP 核文件,下载后替换 demo bundle 中的 IP 核文件即可。
4.3.3.2 学习路径
建议按照以下顺序学习和使用 Xillybus:
- 第一步:理解原理。 阅读官方的工作原理介绍,建立”FPGA 侧是 FIFO,上位机侧是设备文件”这个核心概念。
链接:https://xillybus.com/doc/xillybus-pcie-principle-of-operation
- 第二步:跑通 Demo。 下载对应 FPGA 型号的 Demo Bundle,按照 Getting Started 指南在板子上跑通 loopback 测试,验证 PCIe 链路、驱动安装、数据收发都正常。
`Demo Bundle 下载:https://xillybus.com/pcie-download
Xilinx FPGA 入门指南:https://xillybus.com/downloads/doc/xillybus_getting_started_xilinx.pdf
Linux 上位机入门指南:https://xillybus.com/downloads/doc/xillybus_getting_started_linux.pdf
Windows 上位机入门指南:https://xillybus.com/downloads/doc/xillybus_getting_started_windows.pdf
- 第三步:学习 FPGA 侧接口。 阅读 FPGA Designer’s Guide,搞清楚 FIFO 信号的时序要求、多通道的连接方式、时钟域的处理。
链接:https://xillybus.com/doc/xillybus-fpga-designer-guide
- 第四步:定制 IP 核。 根据自己的工程需求(通道数、位宽、带宽),在 IP Core Factory 生成定制的 IP 核。
IP Core Factory:https://xillybus.com/ipfactory/
定制指南:https://xillybus.com/doc/xillybus-custom-ip-guide
- 第五步:开发上位机程序。 阅读 Host Application Programming Guide,学习同步/异步流的区别、高速数据采集的编程技巧、帧缓冲和数据包通信的实现方法。
`Linux 编程指南:https://xillybus.com/doc/xillybus-host-programming-guide-linux
Windows 编程指南:https://xillybus.com/doc/xillybus-host-programming-guide-windows
- 补充:带宽参考。 不同 PCIe 配置下的理论和实际带宽。
链接:https://xillybus.com/doc/xillybus-bandwidth
- 补充:第三方教程(比官方文档更易上手)。
快速入门:https://www.01signal.com/xillybus/getting-started/
数据采集实例:https://www.01signal.com/xillybus/data-acquisition/
- 官方文档总入口
所有文档(含中文版本)的索引页:https://xillybus.com/doc
- PCIe 带宽速查
| PCIe 版本 | 单通道原始带宽 | x4 实际有效带宽 | x8 实际有效带宽 |
|---|---|---|---|
| Gen1 | 250 MB/s | ~800 MB/s | ~1.6 GB/s |
| Gen2 | 500 MB/s | ~1.6 GB/s | ~3.2 GB/s |
| Gen3 | ~1 GB/s | ~3.2 GB/s | ~6.4 GB/s |
实际带宽约为理论值的 80%,受 TLP 头部开销和协议层开销影响。对于超声成像系统(128 通道 x 12bit x 80MHz = 约 120 MB/s),即使是 Gen1 x4 也绑绑有余。
- 授权说明
Xillybus 的 Demo Bundle 可以免费下载用于评估和学术研究。正式商用需要购买授权。Xillybus Lite(用于 Zynq 的轻量版,走 AXI 而非 PCIe,带宽约 28 MB/s)是完全免费的,没有授权限制。
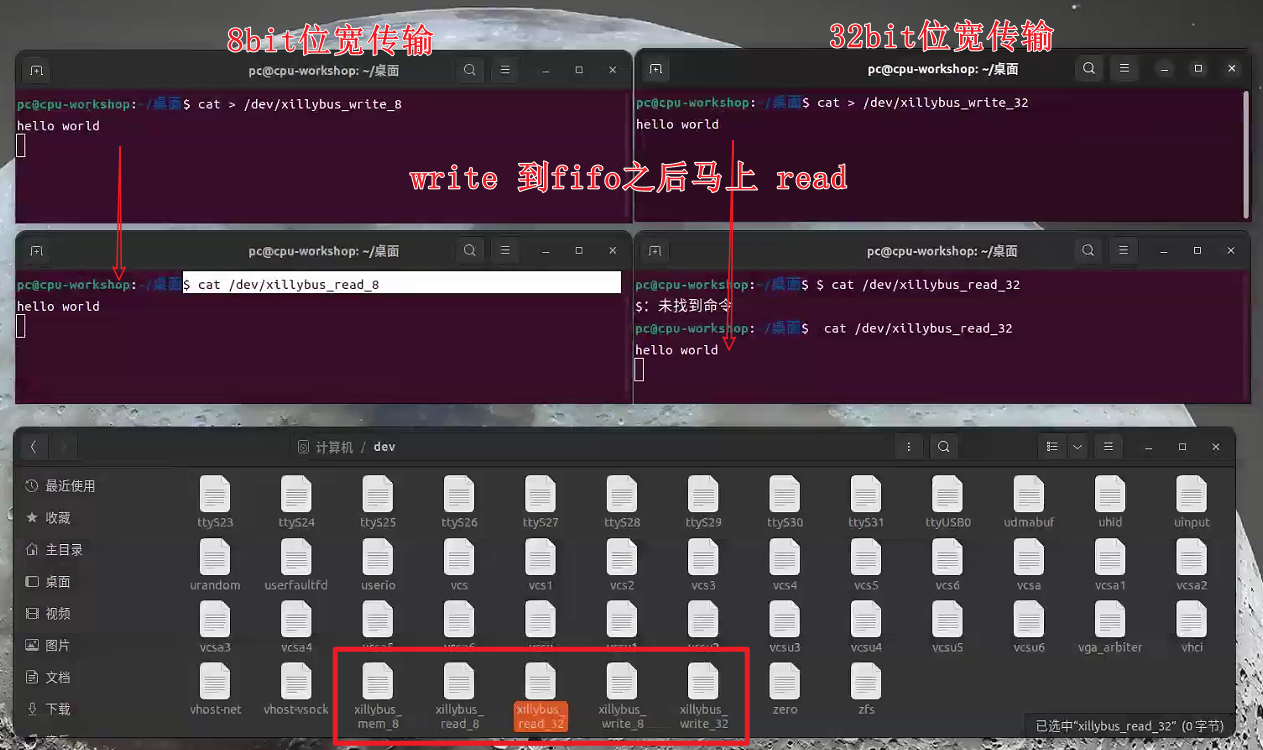
4.3.3.3 官方demo回环实验
4.3.3.4 待整理
- 每次下载bit流都要重启上位机,有没有别的方法,可以不重启,重新刷新pcie设备。
- Xillybus 的 FPGA demo 文档明确写了:对于 PCIe 项目,FPGA 必须在计算机上电前就加载好 bitfile;主机通常不希望 PCIe 卡在系统运行过程中“消失后又出现”。文档还特别说,虽然 PCIe 规范支持 hotplug,但很多主板并不会正确处理这种情况;Xillybus 驱动对 hotplug 较敏感,但整机稳定性没有保证。
- 还是不要乱搞了,因为查了一下,没法直接卸载dev,如果要实现的话必须rmmod卸载内核模块,比如
xillybus_pcie、xillybus_core、xillybus_class。但是这样的话就怕有问题,还是重启吧。
五、IP核版本的切换
在 Vivado 中添加自定义 IP 时,IP Catalog 显示的版本号完全由 IP 目录下的 component.xml 文件决定。如果 IP 存在多个版本的 xgui tcl 文件,但 component.xml 中记录的是最新版本,那么 Vivado 只会识别并展示该最新版本。若需要切换回旧版本,有以下几种方式。
5.1 方式一:修改 component.xml(推荐)
component.xml 是 IP 核的核心描述文件,Vivado 通过读取其中的版本字段来识别 IP 版本。
操作步骤:
- 打开 IP 根目录下的
component.xml - 找到版本字段并修改为目标版本号:
1 | <!-- 将版本号改为目标版本,例如从 3.1 改为 3.0 --> |
- 同步检查 xgui tcl 文件的引用,确保指向对应版本的 tcl 文件,例如:
1 | <!-- 确认引用的是目标版本对应的 tcl 文件 --> |
- 保存后,在 Vivado 中执行 IP Catalog -> Refresh IP Catalog,即可看到切换后的版本。
5.2 方式二:复制独立目录,多版本并存
如果希望多个版本同时出现在 IP Catalog 中,可以为每个版本维护一份独立的 IP 目录。
操作步骤:
- 将整个 IP 目录复制一份并重命名,例如
uiFDMA_v1_0 - 修改该目录下
component.xml中的版本号与名称,使其与原目录区分 - 在 Vivado 的 Settings -> IP -> Repository 中,将新目录添加为 IP Repository
- 刷新 IP Catalog,两个版本将同时可见
注意事项
- 修改
component.xml前务必备份整个 IP 目录,避免误操作导致 IP 损坏。- 如果工程中已经例化了该 IP,切换版本后 Vivado 可能会提示版本不匹配,按提示选择 Re-customize IP 或 Upgrade IP 处理即可。
- 版本号需与 xgui tcl 文件中的定义保持一致,否则 IP Catalog 加载时可能报错。
六、做IP核的公司
做 FPGA IP 核的第三方公司不少,按领域分类列给你:
6.1 综合类 IP 供应商(覆盖多种功能)
Zipcores https://www.zipcores.com/ 英国公司,AMD 官方合作伙伴。IP 种类非常全:视频处理(4K 缩放、HDMI、SDI)、通信协议(以太网、UART、SPI、I2C)、DSP(FFT、FIR、NCO)、编解码(JPEG、H.264)、纠错码(Reed-Solomon、LDPC)等。提供 VHDL/Verilog 源码,可跨平台综合。产品页面分类清晰,适合浏览找灵感。
Sundance DSP https://www.sundancedsp.com/ 英国公司,AMD 合作伙伴。偏向 DSP 和信号处理方向:FFT、正交变换、多相滤波、功率谱,还有 MIL-STD-1553、ARINC 429 等军工航空协议 IP。同时也卖 FPGA 开发板。
iWave Systems https://www.iwavesystems.com/product-category/fpga-ip-cores/ 印度公司,做嵌入式系统和 FPGA IP。涵盖视频(Camera Link、MIPI CSI)、通信(PCIe、USB、以太网)、存储(SATA、NVMe)等。除了卖 IP 还提供 FPGA 设计外包服务。
6.2 通信/网络/存储方向
Missing Link Electronics (MLE) https://www.missinglinkelectronics.com/ip-cores/ 德国公司,专注网络加速和存储加速 IP。核心产品包括 100Gbps 以太网加速、NVMe 存储控制器、PCIe 非透明桥(NTB)。被 AMD/Xilinx 选为停产 IP(如 XPS USB 2.0)的官方长期支持供应商。技术含量很高,面向企业级应用。
Microtronix https://www.microtronix.com/ 加拿大公司,Intel/Altera 生态的 IP 供应商。产品包括 I2C、PCIe、JPEG-LS、LVDS Camera Link、存储控制器等。
6.3 视频/图像方向
OmniTek https://www.intopix.com/ (已被 intoPIX 收购) 比利时公司,专做视频编解码 IP:JPEG 2000、JPEG XS、TICO(低延迟视频压缩)。广播电视和专业影视行业用得多。
Helion (Rambus) 被 Rambus 收购后并入安全 IP 产品线,主要做加密/安全相关 IP。
6.4 开源 IP 生态
LiteX / enjoy-digital https://github.com/enjoy-digital 法国的 Florent Kermarrec 主导的开源项目群。用 Python(Migen 框架)生成 Verilog,覆盖面极广:LitePCIe(PCIe DMA)、LiteEth(以太网)、LiteDRAM(DDR 控制器)、LiteSATA(SATA)、LiteSDCard(SD 卡)、LiteScope(逻辑分析仪)、LiteX-SoC(完整 SoC 生成器)。全部 BSD 开源,商用免费。在开源 FPGA 社区影响力很大。
OpenCores https://opencores.org/ 最早的开源 IP 共享平台,里面有大量社区贡献的 IP:UART、SPI、I2C、以太网 MAC、WISHBONE 总线、OpenRISC 处理器等。质量参差不齐,有些很好有些年久失修,但作为学习参考非常有价值。
PULP Platform (ETH Zurich) https://pulp-platform.org/ 苏黎世联邦理工的开源项目,专注 RISC-V 处理器 IP 核。CV32E40P、CVA6 等处理器核已经被多家公司用于商业芯片。如果你对在 FPGA 上跑软核处理器感兴趣,这是最活跃的开源 RISC-V IP 来源。
6.5 和 Xillybus 最像的(简化 FPGA-PC 通信)
这个细分领域 Xillybus 确实是做得最好的,直接竞品很少。最接近的替代是:
LitePCIe(开源,上面提到了):功能类似但需要用 LiteX 框架,不像 Xillybus 那样拿来就用。
Xilinx XDMA(免费官方方案):功能更强但接口复杂度高得多,不像 Xillybus 的 FIFO 接口那么简洁。
Xillybus 的独特之处在于它做到了”端到端极简”——FPGA 侧 FIFO 接口 + 上位机侧文件接口 + 自带驱动,这个组合在行业里确实没有完全对等的竞品。