超声成像方法与波束形成Beamforming
超声成像方法与波束形成Beamforming
一、超声成像方法
超声成像方法指的是:发射端的方法
1.1 传统方法
1.1.1 电子延迟线扫成像
只要一次发射,经过波束形成后,图像中生成的都是一条线(也就是扫描线,或者说是一个一维向量),那就都是线扫
通过施加电子延迟,实现线扫,
有没有焦点:有,虽然是线扫,但是也要发射聚焦到一个深度点上
1.1.2 电子延迟扇扫成像
只要一次发射,经过波束形成后,图像中生成的都是一条线(也就是扫描线,或者说是一个一维向量),那就都是线扫
1.2 新型方法
1.2.1 合成孔径成像SA
合成孔径成像启发于雷达的合成孔径,传统合成孔径成像可以参考jensen2006年的综述:Synthetic aperture ultrasound imaging - ScienceDirect

其使用一个一个阵元分别激励,使用全孔径接收,比如128阵元,就会产生128帧RF数据,之后在经过波束形成进行成像。
通过单个阵元激励合成孔径成像效果还是提升很大的

1.2.1.1 虚拟点源
虚拟点源是为了提升超声换能器的成像孔径而提出的一种方法。
其工作原理示意图:
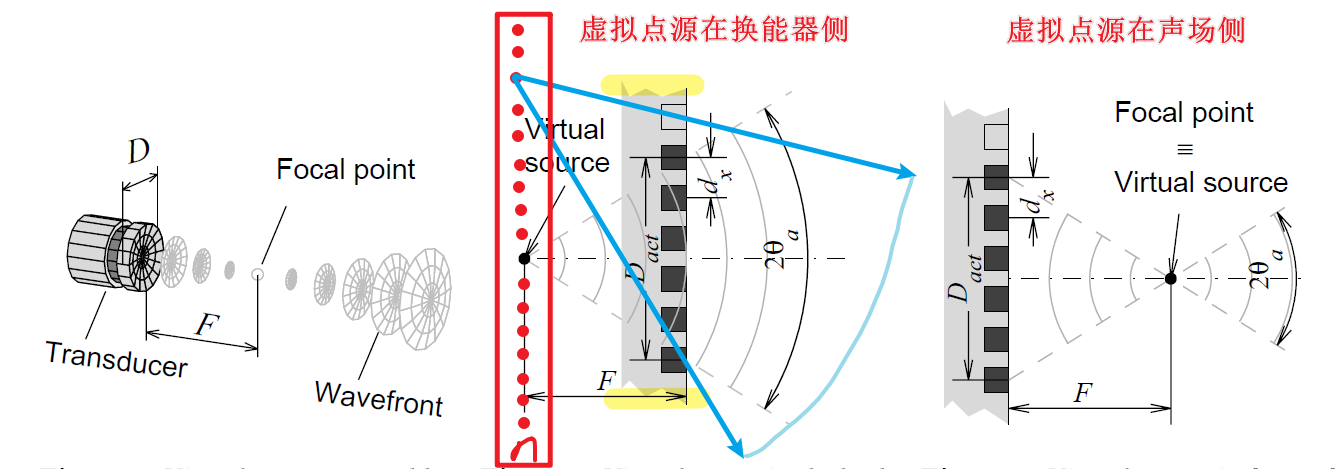
换能器阵列通过施加电子延迟,产生在换能器前或后的一个个虚拟点源。红色的一个个的点即为虚拟点源,可以将他们视为发出超声波的声源,而换能器阵列变成了声波路径上的一些途经点,变得没有意义,可以忽略他们的存在,之后在计算任何delay的时候,只需要考虑这一帧是这一个红色的点源发出的声波即可。
观察虚拟点源在换能器侧示意图,可以看到,本来换能器孔径只有比较小的范围,但是通过虚拟点源方法,相当于扩展了其孔径,理论上其孔径可以扩展的无限大,孔径在一定范围内增大可以大幅提高成像的横向分辨率。如下图所示:

1.2.1.2 虚拟点源在换能器侧
如上上图所示,当虚拟点源在换能器侧时,其就相当于在换能器侧有一个点源发出声波,而不是换能器阵元面发射,后面所有的波束形成等方法都以这个点源作为发射端即可。
1.2.1.3 虚拟点源在声场侧
如上上图所示,当虚拟点源在声场侧时(其实就是相当于使用电子延迟使波束聚焦在声场中一个点上,类似动态聚焦聚焦波),其就相当于在声场侧有一个点源发出声波,而不是换能器阵元面发射,那么这个声波是要先返回换能器面吗?不是的,要强调一下虚拟点源这个概念,在发射时,他就是探头,因此,我们要把他作为一个点源换能器,发射的声波直接向下面的声场传播,发射延迟因此也要改变。
但是接收延迟还是声场中的散射点距离换能器阵元的距离。
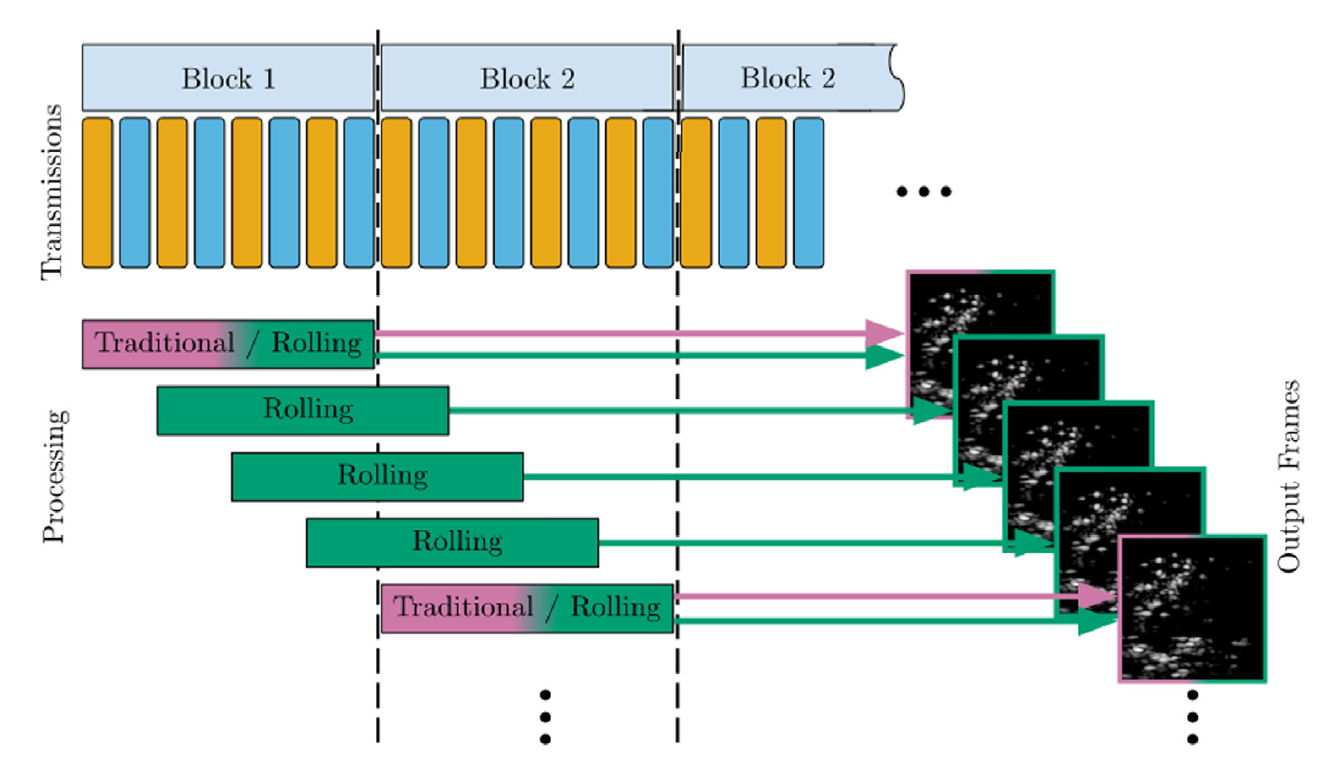
1.2.1.4 合成孔径成像提速:滑动窗口相干合成
1.2.2 平面波成像
平面波成像在原理上可以视为一种特殊的合成孔径成像
1.2.2.1 单角度平面波成像
1.2.2.2 多角度平面波相干复合成像
1.2.3 TO法 横向震动法
二、波束形成方法
2.1 什么是波束形成
波束形成和以上提出的超声成像方法有些杂糅,不好区分,这里我们做下规定:
- 波束形成不包含滤波、取包络、插值、对数变换、加窗、变迹
- 波束形成不包含超声发射方法
- 这里说的波束形成只谈对采集回来的信号进行不同的处理,以实现类延迟叠加的效果
下面正式开始:
- 黑箱理论:一个RF数据被采集回来后,经过一个黑箱,产生图像,被人眼所接收。
那么这个黑箱就格外重要,黑箱里面有什么?
有数据裁剪、滤波、取包络、波束形成、图像滤波、图像去噪、图像锐化、卷积、神经网络识别、大模型分割…….
也就是说,对于一个确定的RF数据(原始数据真实性由传感器决定),后面的黑箱,才是成像是否真、是否有意义的real决定性因素。
其中波束形成也是这里面可操作性最强之一的流程。
- 波束形成来源于自适应天线,接收端的信号处理,可以通过对多天线阵元接收到的各路信号进行加权合成,形成所需的理想信号。
超声中波束形成的定义为:通过数字延时补偿替代传统模拟延时线实现精确信号控制,其关键技术包括动态聚焦、动态孔径调整和幅度变迹,支持逐点跟踪式信号处理。该技术突破模拟系统的通道数限制,显著提升成像分辨率与稳定性。
- 插一嘴,md加矩阵的规定:

2.2 为什么要用波束形成
2.3 DAS (delay-and-sum)
2.3.1 DAS整体流程
DAS即delay-and-sum顾名思义为先延迟再相加,那么对象是谁?没错,对象就是我们通过AD采集回来的RF射频数据,这个射频数据应该有C列,分别对应C个探头;有R行,分别对应采样深度R,即为采样点个数为R。
其实下面说的是矩阵DAS
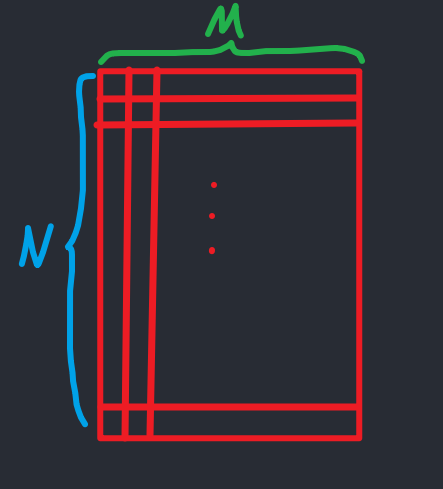
先不考虑图像的插值问题,假设图像矩阵大小与射频矩阵大小一致。DAS的整体流程为:
graph TD
A[换能器信息]-->|构造|C[M*N个延迟阵 每个延迟阵都对应一个image像素点];
B[目标image: I 矩阵 像素数长M宽N信息]-->|构造|C;
C-->D[根据其中1个延迟阵取T中的RF数据并相加];
E[T 矩阵 RF数据矩阵]-->D;
D-->F[得到 I 矩阵中其中一个aij数据]
反复重复以上操作,重复M*N次之后,完整的image矩阵就做出来了,使用这个图像矩阵就可以直接显示了,也可以基于此在做各类的算法进行图像优化。
2.3.2 DAS数学推导
也就是说:
- RF矩阵大小为
- 延迟阵大小为
- 图像阵大小为
- 如上所述,先默认认为,也就是构建的图像矩阵大小与射频矩阵大小相同
现在每个像素点对应一个延迟阵,成像域一共有个像素点,因此一共有个延迟阵D,为,,其中image中的第个像素点数值为:
其中为矩阵内积。注意如果RF数据为,图像想要,上面公式中的T就不能用m,n了,需要使用r,c来替代。
好的,目前,回顾一下,我们已经知道怎么求图像阵了,也有RF射频矩阵,目前不知道的只有延迟阵了,下面来求延迟阵:
我们之前已经假设了图像和换能器的行列数相同,那意味着图像列数与换能器阵元个数相同,图像行数与depth采样深度相同。
这里取为换能器阵列的x横坐标,为1个单位depth的延迟时间。
D矩阵计算步骤:
- 求点到各换能器阵元的距离
- 距离/c——>转换成延迟
- 通过延迟/求出格点的位置,并令这个位置的为1
- 完成D矩阵的构造
到此为止,一个完整的DAS流程就实现了,可以出图喽。
2.3.3 DAS的MATLAB代码实现
2.4 CF (coherence factor)
2.4.1 CF整体流程
先做普通传统DAS,可以参考章曦第一、二篇论文。
普通DAS再对DAS后的信号进行CF计算,如果所有通道延时对齐后相位一致,那么相干求和很强,CF 接近 1;如果这些通道主要是旁瓣、噪声、杂波或者相位混乱,分子不会有效叠加,CF 会变小。
N是用到的阵元。是第i个通道的DAS后的信号。
最后把 DAS 图像乘上这个权重,就能压制低相干区域。
所以 CF 的核心不是“增强强信号”,而是:
奖励跨通道相位一致的信号,惩罚跨通道相位不一致的信号。
这就是它能改善对比度、压制旁瓣和杂波的根本原因。
2.4.2 CF的研究历程
CF从1999年被提出,历经多轮研究,产生了CF、GCF、SCF、PCF、SLSC等工作
《Coherence factor of speckle from a multi-row probe》 提出CF这一方法
《Adaptive imaging using the generalized coherence factor》 这篇是 GCF(Generalized Coherence Factor) 的经典论文,它把 CF 从“只看 DC 分量”推广到“看孔径数据空间频谱中低频能量占比”
《The van Cittert–Zernike theorem in pulse echo measurements》 这个不是 CF 权重算法本身,但它是“超声空间相干性为什么有物理意义”的理论源头。后来的空间相干、SLSC、coherence-based beamforming 都经常从这条理论线展开。
2.4.3 CF数学推导和物理原理
由《The van Cittert–Zernike theorem in pulse echo measurements》展开
同相位引导:如果某个图像点真的有一个强散射体,那么经过正确延时补偿后,各阵元通道的回波应该“同相”;如果这个点只是旁瓣、噪声、杂波、散斑随机干涉或延时不准造成的假响应,那么各通道信号虽然有能量,但相位不一致。CF 就是在衡量“能量到底是同相叠加出来的,还是乱相加出来的”。
这篇文章它把统计光学里的 van Cittert-Zernike 定理推广到脉冲回波超声。并指出随机散射介质在被声束照射后,可以看成一个非相干源;其背向散射声场(背向散射其实就是类似反射)的空间协方差可以被预测,而且对于聚焦发射,背向散射声场的空间协方差与发射孔径函数的自相关成正比。
先从 DAS 开始:
假设有 N 个接收阵元。对图像中的某一个像素点 (x,z),第 i 个阵元接收到的原始 RF 信号是:
如果这个像素点真的是散射点,那么从该点到第 i 个阵元的传播时间是:
DAS 做的事情就是:对每个通道取对应延时位置的信号,然后相加。第 i 个通道经过延时补偿后的数据可以写成:
然后所有通道相加:
这里的 就是经过延时对齐后的通道数据。DAS 的隐含假设是:
如果当前像素点是真实散射点,那么延时补偿后,所有通道的应该相位一致,可以相干叠加。
什么叫“相干叠加”
为了看清楚,先把每个通道写成复数形式:
其中::第 i 个通道的幅度;:第 i 个通道的相位
如果延时补偿完全正确,并且回波主要来自这个像素点,那么各通道相位应该差不多:
这时:
会很大,因为所有复数箭头都朝同一个方向。
如果各通道相位很乱:
那么这些复数箭头会互相抵消,最后的和不会太大。
所以 CF 的核心问题就是:
这些通道信号的能量,是不是以“同相方式”集中到了 DAS 的输出里?
CF 的定义从哪里来
DAS 的相干输出功率可以写成:
所有通道的非相干能量可以写成:
但是为了让 CF 归一化到 0~1,需要乘一个 N(通道数):
这里打断一下
直觉上看“平方的和”好像应该比“和的平方”大,但这里不一定。因为 和的平方里面包含了大量交叉项。关键就在这个不等式:
这个是 Cauchy-Schwarz 不等式。也就是说,和的平方最大可以达到平方和的 N 倍,所以分母必须乘 N,才能把 CF 归一化到 0~1。
举个最简单的例子,假设有 4 个通道,而且完全同相:
s1 = 1
s2 = 1
s3 = 1
s4 = 1那么:和的平方 = 16;平方的和 = 4
所以不是平方的和更大,而是同相叠加时,和的平方会变成平方和的 N 倍。
为什么和的平方会更大?把它展开就清楚了。
如果所有通道完全同相,交叉项全是正贡献,所以“和的平方”会被交叉项放大很多。
如果通道相位乱,交叉项互相抵消,这时候“和的平方”就不会大。
回到正题
如果所有通道完全同相,CF 接近 1。
如果所有通道相位混乱,CF 接近 0。
所以:
这说明 CF 本质上是一个归一化相干度指标,不是普通幅值,也不是普通能量。
可以把每个通道的延时后信号看成一支箭头。
如果是真实聚焦点:
1 | ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ |
所有箭头方向一致,相加之后很长,CF 高。
如果是旁瓣、噪声、散斑随机干涉:
1 | ↑ ↘ ← ↗ ↓ → ↙ ↑ |
每个通道都有幅度,但方向不一致,相加后互相抵消,CF 低。
CF 进一步问:
这个和,是不是由一组相互一致的通道信号产生的?
从空间协方差角度理解 CF
现在把 CF 和 Mallart-Fink 论文联系起来。
论文中定义的空间协方差,本质上就是看两个不同位置接收到的声场是否相关:
也就是:阵元 1 和阵元 2 接收到的回波是否相干。论文明确把背向散射压力场在两个位置的相关性作为空间协方差来分析,并指出这个定义来自散射介质的统计性质。
CF 其实也在做类似的事情,只不过它不是显式计算完整的协方差函数,而是对当前像素的所有通道做一个整体相干度评价。
把 CF 的分子展开:
这里面有两类项。
第一类是自能量项:
第二类是交叉相干项:
所以 CF 可以写成:
这就非常关键了:
CF 高不高,主要取决于不同阵元之间的交叉项 是否同相为正。
如果通道之间相位一致,交叉项大量正向叠加,CF 高。
如果通道之间相位乱,交叉项互相抵消,CF 低。
这就是 CF 的物理本质:
CF 是对接收孔径内通道间空间相干性的压缩评价。
为什么散斑也和相干性有关
普通组织不是一个孤立点目标,而是很多随机散射子组成的介质。一个分辨单元里有大量随机散射子,它们的回波在接收端随机干涉,形成 speckle。
Mallart 和 Fink 的论文里也强调,speckle 与超声束的空间相干性以及介质的随机性质有关,本质上来自一个分辨单元内随机反射体之间的干涉。
这点对 CF 很重要。
因为 CF 不只是压制电子噪声,它还会改变散斑纹理。对于一个完全发展的散斑区域,通道之间并不一定像单个点目标那样完全相干,所以 CF 可能会降低某些散斑区域的亮度。
所以 CF 的效果一般是:
1 | 主瓣强目标:保留 |